After reading 2.2, we now understand the operating principles. Let’s deepen the understanding by discussing some important sensor properties and getting to know with Bayer pattern.
Sensor noise and signal-to-noise ratio
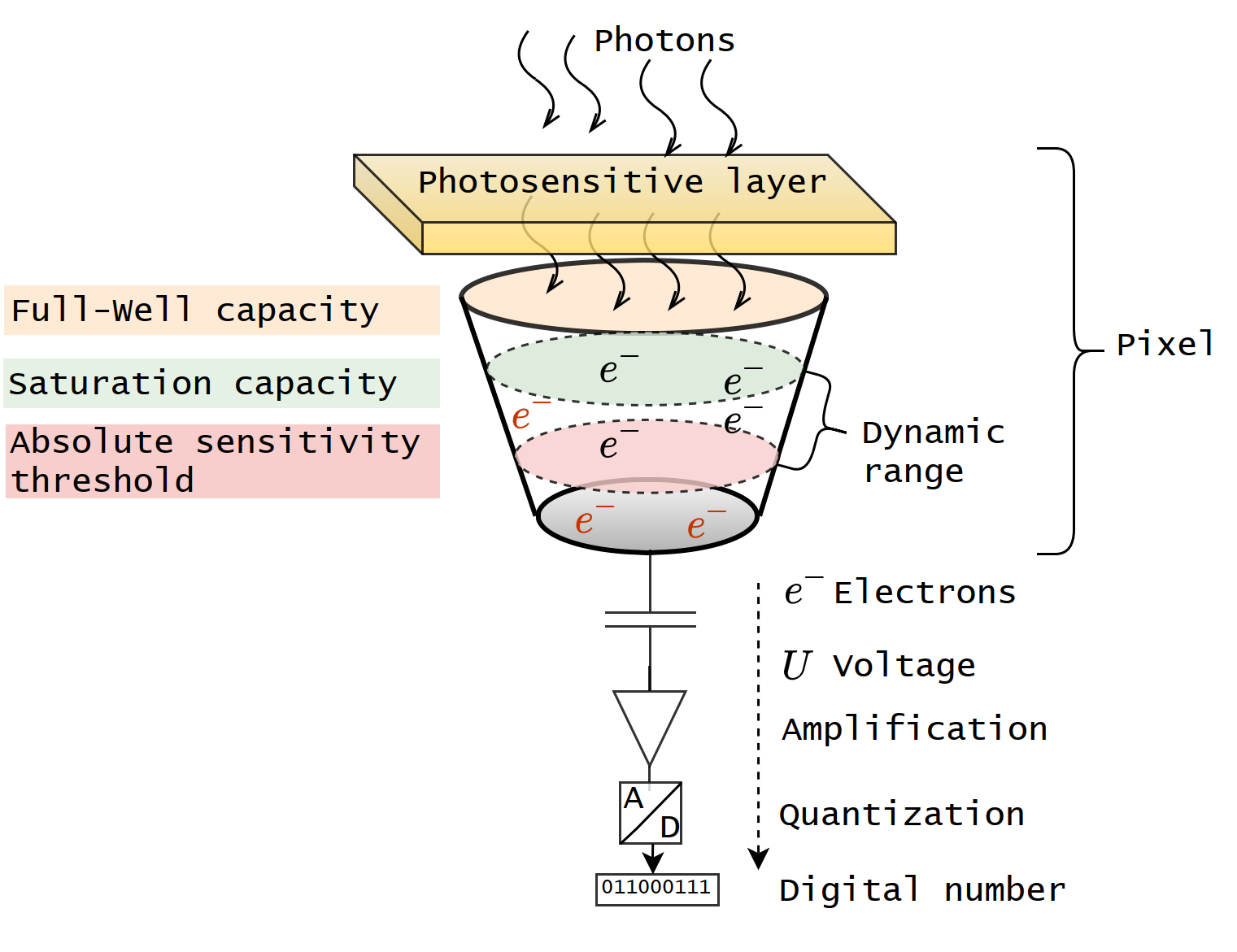
Sensors have different sources of noise. Dark current noise occurs when the electrons emerge through thermal processes in the pixel. The level is related to temperature and exposure time by increasing with them. Photon noise is caused by light, as the photon flux striking the sensor is Poisson-distributed (EMVA 2016). This limits the maximum signal-to-noise ratio (SNR). Readout noise occurs when the electrons are converted into voltages. The quantisation noise is caused when the voltages with continuous values are converted to digital values with discrete values (A/D-conversion). Temporal noise is a combination of all the aforementioned sources of noise. It exists even when the pixels are not illuminated. The exposure time and temperature generate electrons without light. The level of a dark signal varies.
The signal-to-noise ratio is the ratio between the maximum signal and the noise floor. It describes a real signal after the A/D conversion. When the signal-to-noise ratio is 1, the maximum signal and noise floor levels are equal (EMVA (2016) and Stemmer (2022)).
Sensor sensitivity and spectral response
The quantum efficiency and background noise influence the sensitivity of the sensor. The sensitivity is high when the quantum efficiency is high and the background noise level is low. The background noise level is measured with the lens covered. Each pixel has an absolute sensitivity threshold (AST), which describes the lowest possible number of photons with which the sensor can produce a useful image. The sensitivity of a sensor increases when the threshold decreases. The absolute sensitivity threshold is a significant variable in low-light applications. Absolute sensitivity threshold combines the quantum efficiency, dark noise and shot noise values and it is determined when the signal-to-noise ratio level is 1 (EMVA (2016); Stemmer (2022) and Baumer (2022)).
Spectral response describes the wavelength range that a sensor can capture. Typically, the CMOS sensor’s range is from 350 nm to 1100 nm (EMVA 2016). Some CMOS sensors might have enhanced sensitivities for VNIR imaging at the range of 700 – 1000nm. The spectral imagers used for IR applications can use InGaAs sensors that have a range of 900 to 1700 nm or SWIR sensors. The UV sensors’ spectral sensitivity ranges upwards from 200 nm (EMVA 2016).
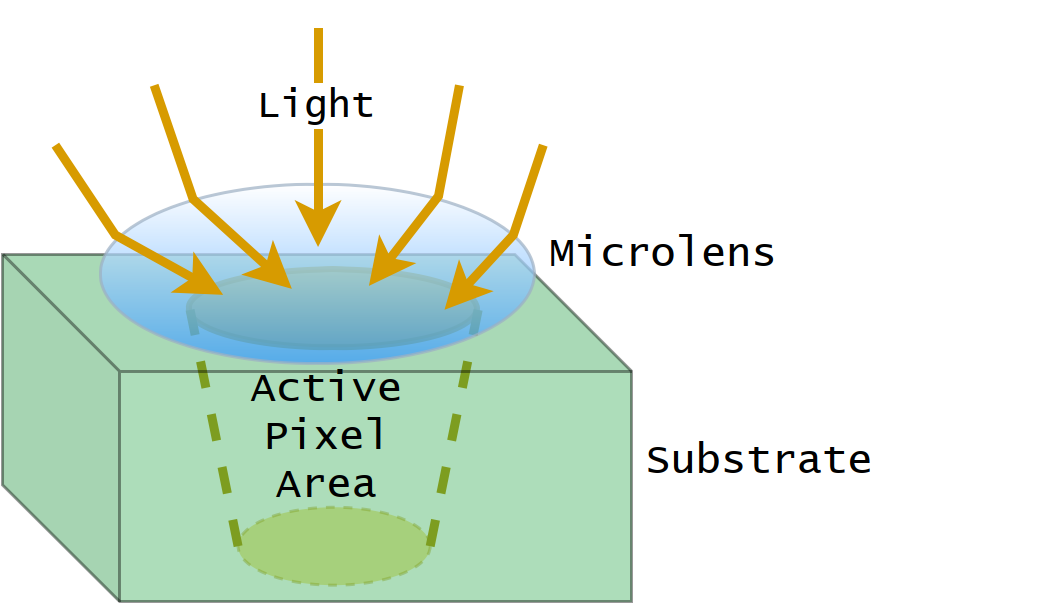
The number of active pixels in a sensor is called spatial resolution. The optimum resolution should be calculated target-wisely for robust inspection systems. The key is to use the measures of the smallest feature in the field of view, which defines the minimum resolution. As a practical example, suppose the feature size is 1 × 1, the object size is 100 × 100, and the analysis method requires 3 × 3 pixels per one feature. The minimum resolution is addressed by multiplying the object size with the requirement: 300 × 300 pixels (Stemmer 2022). The mentioned formula is for monochromatic sensors. The minimum resolution for a colour sensor with a Bayer pattern should be doubled. (What is a Bayer pattern, see figure 1)
Spatial resolution and shutter types
The sensor shutter type describes how the sensor exposes the pixels. A rolling shutter starts and stops the exposure sequentially, row-by-row or pixel-wise. The delay of all pixels to be exposed can be up to 1/framerate, which can be an issue when the target moves (Stemmer 2022). A rolling shutter sensor might have a global shutter start, which allows all pixels to be activated for exposure simultaneously but turned off sequentially. This mode might cause some blurring to the bottom areas of the image, and its use demands a proper illumination design. The global shutter activates and deactivates its pixels at once, being the most practical choice in most applications dealing with moving targets.
Monochromatic and colour sensors and Bayer pattern
Sensors can be divided into monochromatic and colour sensors, and the selection should be made depending on the target. The main difference between monochromatic and colour sensors is the colour filter placed in front of the pixels. A sensor with a pixel-wise filter provides colour filter arrays (CFAs) that can be computed to colour images using demosaic algorithms. In contrast, the monochromatic sensor provides data that can be processed as an image directly.
The CFA limits the sensitivity of each receiving pixel well into a single part of the visible spectrum. Therefore, each red-green-blue (RGB) channel’s CFA pixel has a limited spectral range, representing either red, green or blue spectral responses (Alleysson et al. 2003). The CFA filter is part of the imaging system’s spectral sensitivity, which is determined as a combination of the sensor sensitivity and the transmittance of the CFA filter, such as Bayer blue-green-green-red (BGGR) (Sadeghipoor et al. 2012).
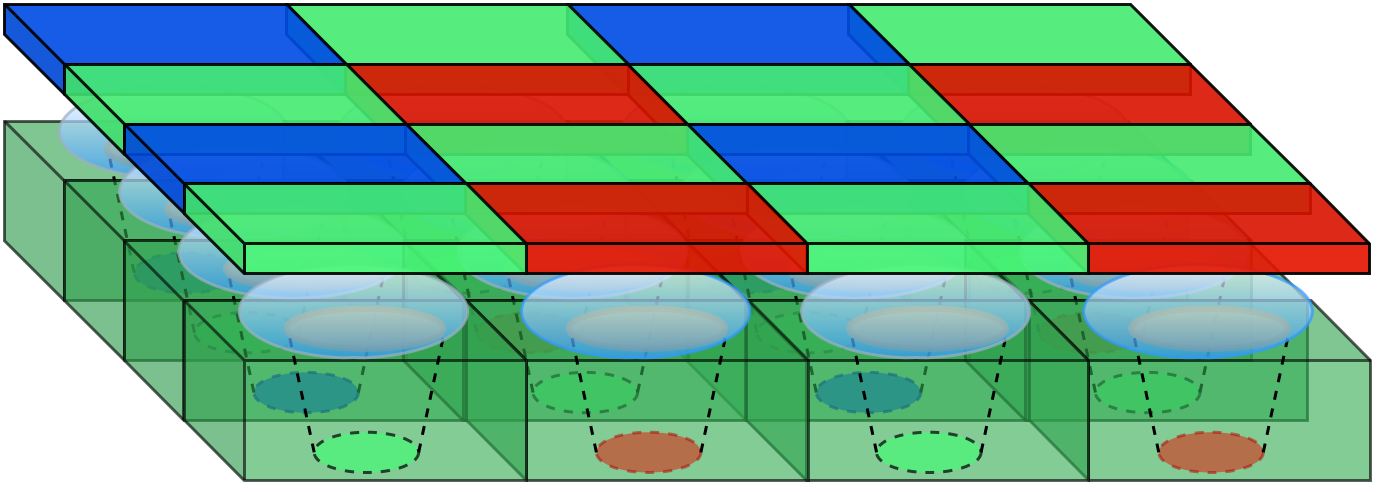
Above, Figure 1 visualises the Bayer pattern BGGR filter placed in front of the sensor. Bayer BGGR filter is a common RGB filter, repeating patterns of 2 × 2 pixels: one blue, two green and one red. Demosaic algorithms perform an interpolation that estimates the three-pixel values of the RGB image Eskelinen (2019).
Wish to know how to pre-process a colour filter array? See 2.4
Found something useful? Wish to cite? This post is based on my dissertation. For citations and more information, click here to see the scientific version of it.
References
Eskelinen, M. 2019. Computational methods for hyperspectral imaging using Fabry-Perot interferometers and colour cameras. URL:http://urn.fi/URN:ISBN:978-951-39-7967-6.
Sadeghipoor, Z., Lu, Y. M. & Süsstrunk, S. 2012. Optimum spectral sensitivity functions for single sensor color imaging. In Digital photography VIII, Vol. SPIE, 26–39. doi:https://doi.org/10.1117/12.907904.
More information
Baumer 2022. Baumer Group, Operating principles of CMOS sensors. URL:https://www.baumer.com/es/en/service-support/function-principle/operating-principle-and-features-of-cmos-sensors/a/EMVA1288. (A leading manufacturer of sensors, encoders, measuring instruments and components for automated image-processing. Accessed on 7.4.2022).
EMVA 2016. The European machine vision association, EMVA Standard 1288, Release 3.1. https://www.emva.org/standards-technology/emva-1288/emva-standard-1288-downloads-2/⟩. (Sensor and camera standards. Accessed on 8.4.2022).
Stemmer 2022. Stemmer Imaging, The Imaging and Vision Handbook. ⟨URL:https://www.stemmer-imaging.com/en/the-imaging-vision-handbook/⟩. (A leading international machine vision technology provider. Accessed on 7.4.2022).